Retargetable Compiler for Hybrid Architectures
We are developing a compiler that converts C-code into a general-purpose CPU code and FPGA code based upon a hardware specification and performance requirements.
Hybrid Architecture
Motivations for Research
What Is a Hybrid Processor?
Hybrid processors combine two traditionally separate types of computational devices
on a single chip. Current commercial hybrid chips provide fixed processing cores and
Field Programmable Gate Array (FPGA) elements to permit customization. By including
an FPGA with a fixed processor, you obtain a performance and power benefit over that
which is available with generic processors, while retaining more flexibility than
an Application Specific Integrated Service (ASIC) can provide.
How Do We Use Them?
Hybrid chips seem uniquely qualified to allow designers to optimize and configure
the available resources for their applications. However, currently available tools
require substantial knowledge of hardware and significant human interaction to obtain
the performance and power improvements.
To realize the potential of hybrid computing systems, we need automated tools to map application programs to existing hardware. While the goal of hardware and software co-design is to design hybrid hardware specifically optimized for a single application, our goal is to map applications written in a procedural programming language to a hybrid architecture that has already been specified. Using the fully automated tool Hy-C, we will evaluate the potential of hybrid computing to execute a wide range of programs that are efficient both in execution time and power consumption.
How Do We Evaluate The Hybrid’s Potential?
To evaluate our hybrid computing model, we need a tool to iteratively partition, analyze,
and repartition input source code to execute in either FPGA or CPU. Since we wish
to evaluate potential of different hybrid architectures, it is insufficient to build
tools that are applicable to only a single architecture. Therefore, evaluation of
hybrid computing potential requires the ability to easily target our code generation
tools to a wide range of multiprocessor and multi-FPGA architectures to allow for
experimentation.
The Hy-C tools will map the C language to a given architecture. Thus, Hy-C will provide the infrastructure necessary to evaluate the potential of hybrid computing.
The tools will facilitate research in hybrid computing. Our Hy-C infrastructure design relies on three principles:
- Re-use available research tools.
- Ease of use.
- Inserting new tools and modifying existing tools should be simple.
Design using these principles facilitates system-level and tool-level research within Hy-C.
The Hybrid Computing Model
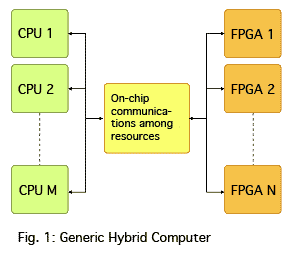
Figure 1 illustrates our schematic view of a generic hybrid architecture. Current hybrid chips provide fixed processing cores and reconfigurable resources (represented as FPGAs in Figure 1), permitting customization.
Reconfigurable resources could just as easily be ASICs or some combination of ASIC and FPGA resources. Because current hybrid chips contain CPUs and FPGAs, we limit our initial studies to hybrid chips containing only CPUs and FPGA resources; however, we anticipate to also support ASIC components in the future.
The biggest obstacle of a hybrid approach is the difficulty of mapping high-level programs to efficient machine-level structures to take full advantage of provided hardware. Currently available mapping tools are limited in their generality and scope. A major goal of our research is to provide this flexible and general mapping.
Figure 2 provides a high-level view of how our tools will generate code for hybrid architectures, based upon the generic target system architecture of Figure 1.
What Tools Generate the Hybrid Architecture?
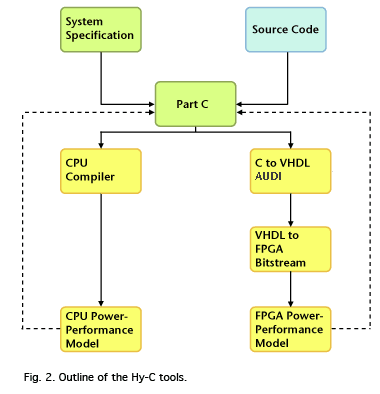
As shown in Figure 2, our code-generation tools can be divided into a few basic parts: system specification describes the computing resources and communication protocols Part C partitions source onto CPUs ad FPGAs fixed-CPU C compilers compile C high-level synthesis tools convert VHDL to FPGA bit-stream SPARK (UC San Diego) converts behavioral C to VHDL performance and power estimation tools.
Our code-generation tools will make significant use of available compiler, CAD, and power-estimation tools. We plan to build only those tools necessary to fill in the gaps in current hardware and software co-design, shown in yellow in Figure 2. Those parts of Hy-C that will require significant new implementation are shown in green.
What Do the Tools Do?
Given a system specification and application source code, our tools first partition
work among the processing resources. After successful partitioning, separate translation
tools for both the general-purpose CPU, high-level synthesis transformations, and
FPGA components generate a machine-level program for the specific computational resources.
At this point, each processing resource accesses performance power models to provide an accurate estimate of the performance and power characteristics of the runtime program. We can then feed this information back to the partitioning phase to consider a possible repartitioning of the computation. By supporting an iterative partitioning process, we can refine code generation for the hybrid system, selecting that partitioning which best meets the optimization requirements of execution performance and power constraints.
Example Application: Matrix Multiply
Software pipelining is a common technique that compilers use to extract fine-grained parallelism from loops. The basic idea of software pipelining is to modify a loop so that multiple iterations of that loop execute in parallel. However, two factors limit the potential performance of software pipelining; namely, the presence of loop-carried dependences and the number of available computing resources (typically, functional units).
Limitations of Software Pipelining
Dependences limit the ability to overlap loop iterations. Resource constraints limit
the amount of computation that can be performed in parallel. Many loops lack dependence
constraints, however, thus making resource constraints (typically, the number of functional
units) the only limiting factor. In fact, Rau found that 83% of software-pipelined
loops were limited by resources rather than by dependence.
Matrix multiplication is an excellent example of this. Since the innermost loop contains no loop-carried dependence, the only limit to parallelism is the number of multiply-accumulate functions that can be started at any point in time.
Consider TI’s family of DSP chips. They allow up to eight distinct operations to complete in one cycle. In theory, then, these chips allow for reading four source operands (for two loop iteration’s multiply-accumulates), two multiply-accumulates for different loop iterations, and for two writes of values for yet two more loop iterations, completing two inner-loop iterations per cycle. But, could we do better? For a fixed CPU, we could only do better if more functional units are available.
Potential of Hybrid Architecture
In contrast, consider using a hybrid architecture’s FPGA to perform multiply-accumulates
in parallel. Instead of being limited by a fixed processor’s hardware, we may compute
as many inner loop iterations in parallel as we can program in the FPGA. So the question
of interest becomes: With the available FPGA resources, how many parallel sets of
two loads (for input values), one multiply accumulate, and one store can be executed
in parallel?
To answer this, we compared a matrix multiply in which the innermost loop was pipelined in FPGA to one executed in a CPU. We assume all data are prefetched into FPGA (Xilinx Vertex5 XC5VLX220, the most powerful FPGA at present). The process to compute matrix c[i][j] was parallelized and pipelined so that it could be completed in one clock cycle. The results are summarized in the following table:
| N=2 | N=4 | N=8 | N=16 | N=32 | |
|---|---|---|---|---|---|
| CPU (ns) | 110 | 875 | 5,500 | 42,500 | 350,000 |
| FPGA (ns)=n² x clock = 6.954 x 4 | 28 | 109 | 635 | 2,549 | 13,865 |
We limited our calculations at N=32 since for a size of 64 would exhaust the resources of any existing FPGA chip. Still, we can see that using the FPGA we can improve inner loop performance by a factor of 25.